TL/DR: Fetching data isn’t just about making API calls—it’s a multi-step process involving triggers, authentication, and parsing. This section walks you through each step of a data request, with real-world examples and pitfalls to avoid.
This article was written by Andrea Kuruppu, our superstar Data Engineer 🌟 Since we cover a lot of concepts here, we divided it into parts:
- Part I: The basics - Fetching the Data (you’re reading this!)
- Part II: Data Processing and Pipeline Optimization
- Part III: Security - Managing Secrets and Authentication with a Proxy API
- Part IV: Version Control and Collaboration
- Part V: Testing, Debugging, and Deployment
- Part VI: Closing Thoughts - Challenges and Best Practices
- Part VII: Summary
Part I: The basics - Fetching the Data
A few weeks ago, I was on a mission to get the latest Shokz earphones—the bone-conduction kind, but with separate, non-interconnected earbuds. I first stopped by my local electronics store, but they didn’t have them in stock. The store attendant checked their online inventory, confirmed they had them available in the warehouse, and let me place the order and pay right there in the store.
Since I was excited to try them out, I opted for express delivery. I kept checking my inbox for updates and tracked the package obsessively once I saw the “out for delivery” email. I even alerted my building manager to buzz me when the courier arrived because my unit’s buzzer was acting up.
Simple story on the surface, but when you think about it, that single purchase depended on multiple systems working behind the scenes—inventory lookup, payment verification, delivery scheduling, real-time tracking, and coordination with building access.
That’s a great analogy for data fetching in engineering. It may seem like just sending a request and getting a response, but in reality, it’s a chain of coordinated steps where any weak link—like a failed auth or a delayed response—can break the whole flow.
More Than Just a Request and a Response
When people hear “fetching data,” they often picture something simple: make a request, get a response. But in production-grade applications, it’s more like ordering those earphones—a multi-step process where each stage relies on the success of the one before it.
Think about something as familiar as Instagram: when you open the app, your feed doesn’t just appear instantly. Behind the scenes, the app authenticates your session, requests new posts based on who you follow, fetches those posts in batches, loads the media files from a CDN, and finally renders the UI. Each of those steps involves multiple systems, APIs, and data sources all working together in real time.
Whether you’re syncing data from a partner API or powering a dashboard, it’s rarely just one request—it’s a chain of requests, responses, retries, validations, and fallbacks. And like the earphone delivery, any failure in the chain can disrupt the experience.
The Data Fetching Journey (Like Ordering a Package)
Let’s break it down.
Just like ordering a product online involves multiple steps—checking stock, payment, packaging, and delivery—data fetching in engineering follows a multi-stage journey. Each step has its logic, tools, and potential for things to go wrong.
Here’s a simplified visual that maps the process in a field-tested data flow:
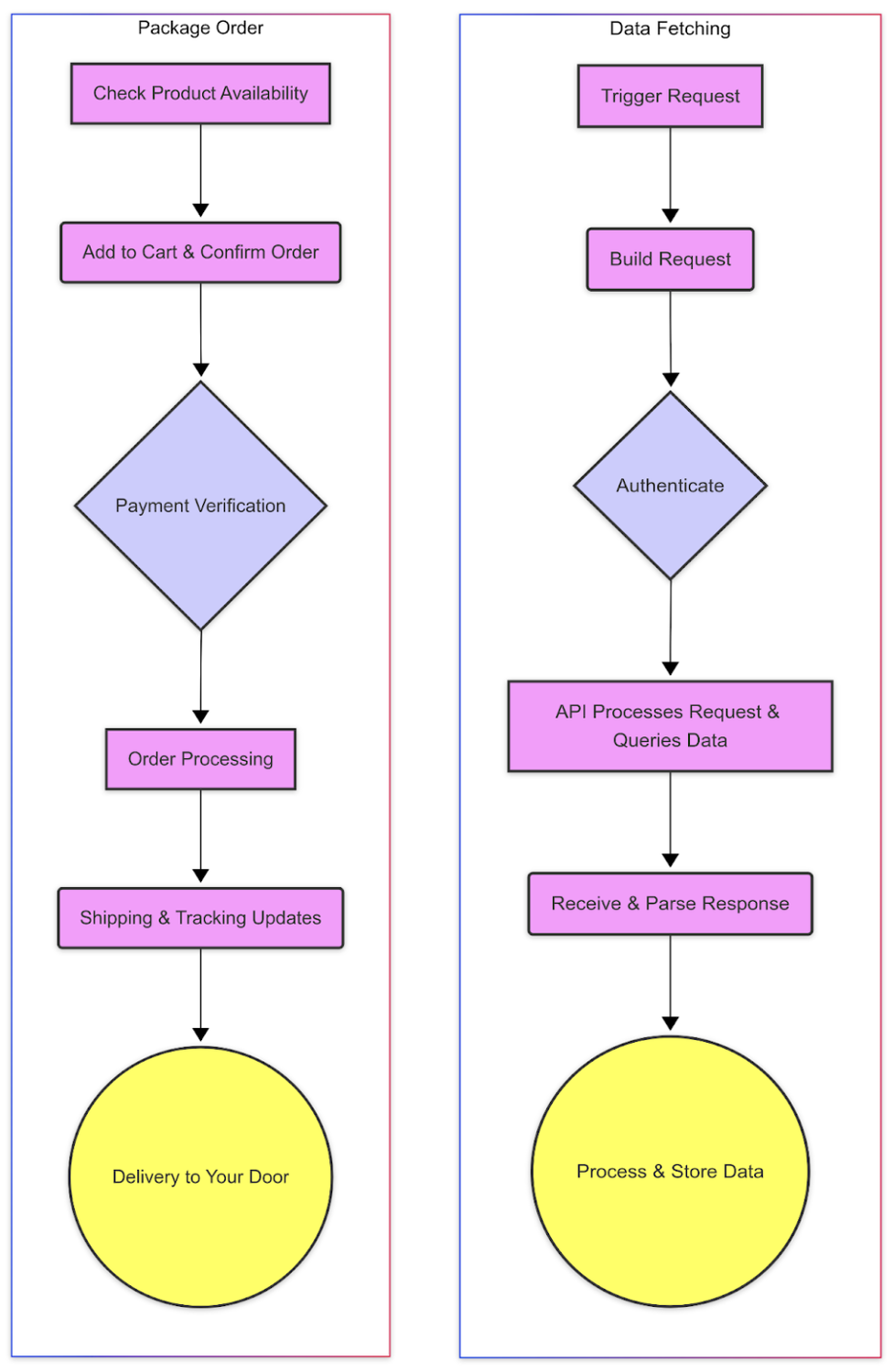
- Trigger Event – Something initiates the fetch: a scheduled job, user action, or dependency update.
- Build Request – You prepare the request with the right URL, parameters, and headers.
- Authentication – Secure access using an API key, token, or OAuth.
- Send Request – You send the request across the network.
- Server Processes It – The server receives it, runs a query or process, and assembles the data.
- Receive Response – The client receives the response—ideally with the data you asked for.
- Parse + Validate – You parse JSON, XML, or CSV, check for errors, and make sure it fits your schema.
- Transform & Sync into Pipeline – The data is transformed, filtered, and written into your data flow.
Each of these steps introduces challenges:
- Authentication can fail due to expired tokens.
- Requests might time out or hit rate limits.
- Responses might be paginated or partially missing.
- APIs change without notice, breaking your logic overnight.
And when you’re dealing with multiple data sources or large datasets, these problems don’t just add up—they multiply.
What Is Data Fetching?
At its core, data fetching means getting data from an external source—like an API, a database, or a cloud service—and bringing it into your application or workflow.
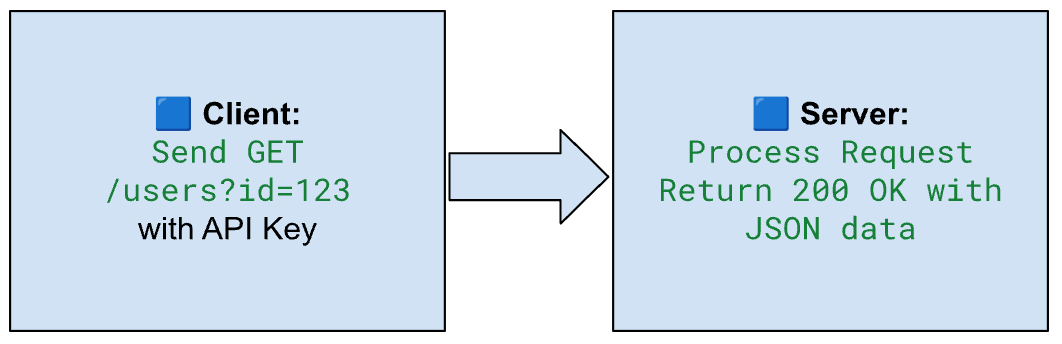
Think of it as asking a system for information and waiting for it to give you a reply. To contrast with the full system lifecycle, here’s what a basic request–response exchange looks like at a high level:
That system might be an API endpoint that returns user activity logs, a SQL database storing customer records, or a cloud storage bucket with CSV files.
Why It Matters
In modern data engineering, data fetching is where everything begins. Before you can transform, analyze, or visualize data, you first need to get it—accurately, securely, and efficiently.
Whether you’re:
- Building a dashboard that updates every hour
- Powering a recommendation system with real-time signals
- Syncing customer data between platforms
…you need reliable, automated ways to fetch and ingest data from external systems.
Poor data fetching can lead to slow data flows, incomplete results, and painful debugging. Well-designed fetching, on the other hand, lays the foundation for everything else to run smoothly.
Common Types of Data Sources
Here are some of the most common places we fetch data from:

In my recent project, I worked with multiple APIs—each with its quirks, rate limits, and authentication systems. Designing connectors for these was where I started to truly understand how much work goes into simply “getting the data.”
Up next, I’ll show you how data fetching works behind the scenes, step by step—so you can see what happens between the request and the response.
The Lifecycle of a Data Fetch Request — Step by Step
Fetching data isn’t a single click-and-done operation—it’s a sequence of steps, each one critical to the success of the whole process. Let’s walk through the full lifecycle, using field-tested workflows examples from a recent project I worked on.
1. Triggering the Request
Something needs to kick things off. In data engineering, that could be:
- A user action (like refreshing a dashboard).
- A scheduled job (e.g., every 15 minutes or daily at midnight).
- A workflow trigger (like a file arriving in a cloud bucket or a prior task finishing).
In modern data systems, these triggers are often coordinated through orchestration tools like Apache Airflow, Dagster, or cloud-native solutions like Google Cloud Workflows. These tools help manage dependencies and ensure that steps run in the right order at the right time.
In our data flow, the syncs were mostly scheduled jobs, but sometimes triggered by dependency updates—for example, waiting for an upstream system to finish writing before starting our fetch. These dependency-based triggers help ensure you’re fetching data only after the upstream system has finished writing or aggregating it—preventing issues like partial results or duplicate fetches.
Triggers are where logic and timing meet: set them too early, and you fetch stale data; too late, and downstream systems lag. Thoughtful triggering is what separates a reliable job stream from a flaky one.
2. Constructing the Request
Once the trigger fires, the next step is building the actual API request. This means crafting a request that the target service understands and accepts.
Key elements include:
- Choosing the HTTP method – Usually GET for retrieving data, but sometimes POST if the request body is required.
- Adding headers – Including essentials like Content-Type and Authorization.
- Setting query parameters – Useful for filtering, pagination, or specifying date ranges.
- Handling authentication – Using API keys, bearer tokens, or full OAuth flows.
In practice, request construction is often handled by reusable connector functions that assemble the full request step by step. Pagination parameters like offset or next_token are added dynamically depending on prior responses. Likewise, headers and tokens are usually injected just before the request is sent—allowing code to remain modular and consistent.
In my project, one of the most important tasks was developing and debugging connectors that could handle multiple authentication methods. Managing OAuth token refreshes was especially tricky but crucial: without it, connections could silently expire in the middle of a sync job.
Here’s a breakdown of the key components that go into a well-formed API request:
API Request Structure – Quick Breakdown

We implemented logic that automatically:
- Detected when a token was close to expiring.
- Fetched a new token using a refresh token.
- Retried the original request after refreshing credentials.
We implemented this via a wrapper around our HTTP client, which transparently intercepted requests and refreshed tokens when needed. We also added exponential backoff for retries, which made the system resilient to intermittent failures like 401s or rate limits.
This proactive approach helped us avoid subtle, hard-to-detect failures in long-running jobs—and made our connectors more reliable in production environments.
3. Sending the Request & Server-Side Processing
Now the request goes out over the network. Here’s what happens:
- The client sends the request to the API.
This is the moment where all the preparation pays off—your headers, authentication, parameters, and method are bundled and transmitted.
- You have to consider network latency, timeouts, and retries.
Network conditions are unpredictable—latency spikes can slow things down, and services sometimes fail mid-request. To make your job stream more reliable, it’s common to add retry logic with exponential backoff: reattempting a failed request after a delay that increases with each try.
Timeout settings are equally critical: too short, and you risk prematurely cutting off services that are just slow; too long, and you may hang indefinitely waiting on an unresponsive API. In our connectors, we tuned these values based on practical response patterns, and added circuit-breaker logic to halt retries when systems were clearly down—avoiding unnecessary load and wasted compute.
- On the server side, the API processes the request, queries its database, and returns the result
Depending on the endpoint and query, this might involve filtering, joining, or transforming data before the response is sent.
Here’s a simplified visual of what happens between client and server during the request–response cycle:
Visual: How a Client Request Travels and is Processed on the Server
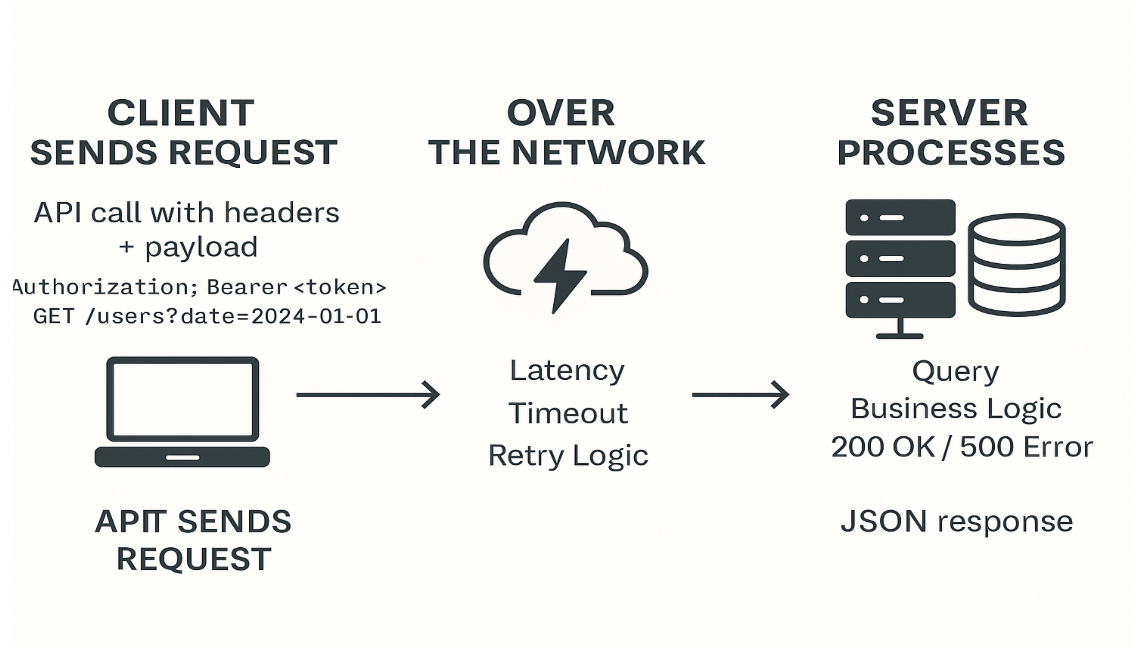
I spent time researching API permissions, which sometimes restricted what data we could access. I also learned to choose between GET and POST based on payload size and endpoint constraints—a small tweak, big impact on performance.
4. Receiving and Parsing the Response
If the request succeeds, you’ll get a response—usually in JSON or XML. Now your code needs to:
- Check the status code: Before you even look at the response body, inspect the status code. A 200 OK means all is well, while a 404 Not Found might mean the endpoint is incorrect or the resource is missing. 500-level errors often point to server-side issues.
Example:
if response.status_code != 200:
raise Exception(f"Unexpected status: {response.status_code}")- Handle errors gracefully, including retries or fallbacks Don’t crash on the first error. Implement retries for transient errors and define fallback behavior for persistent failures.
Example:
for attempt in range(max_retries):
try:
response = requests.get(url)
if response.status_code == 200:
break
except requests.exceptions.RequestException:
time.sleep(2 ** attempt) # exponential backoff
else:
log.error("Failed after retries")- Parse the data into a usable format (objects, records, etc.) Most responses are in JSON. You’ll need to deserialize them and sometimes map the result into your domain model.
Example:
data = response.json()
users = [{"id": u["id"], "name": u["full_name"]} for u in data["results"]]Robust error handling became a must. APIs changed their formats more often than you’d think, and having a parser that could adapt to unexpected fields or types saved hours of debugging later.
Once the API sends back a response, the real work begins: parsing it, validating the data, and sometimes looping through multiple pages of results. Below is a short code example that demonstrates how we handled paginated API responses with error handling and schema validation in our data flow.
Example: Parsing Paginated API Responses with Error Handling and Schema Validation
import requests
def fetch_data():
url = "https://api.example.com/data"
headers = {
"Authorization": "Bearer YOUR_TOKEN",
"Accept": "application/json"
}
all_records = []
page = 1
while True:
try:
response = requests.get(url, headers=headers, params={"page": page})
if response.status_code != 200:
print(f"Error: Status {response.status_code}")
print("Response:", response.text)
break
data = response.json()
# Validate expected schema
for item in data.get("results", []):
if "id" in item and "name" in item:
all_records.append(item)
else:
print("Skipping invalid item:", item)
# Check if there's another page
if not data.get("next_page"):
break
page += 1
except requests.exceptions.RequestException as e:
print("Request failed:", e)
break
print(f"Fetched {len(all_records)} valid records.")
fetch_data()5. Processing the Data in the Pipeline
Now that the response has been successfully parsed, the next phase begins: transforming and preparing the data for downstream use.
- Validated against your schema (do fields match what you expect?)
- Transformed (e.g., renaming fields, converting timestamps)
- Filtered or enriched before being written downstream
In our case, we added support for pagination and incremental sync—only fetching new or changed records using checkpoint logic. That made the process faster and more scalable, especially when pulling from large datasets.
Keep reading this series:
- Part I: The basics – Fetching the Data
- Part II: Data Processing and Pipeline Optimization
- Part III: Security – Managing Secrets and Authentication with a Proxy API
- Part IV: Version Control and Collaboration
- Part V: Testing, Debugging, and Deployment
- Part VI: Closing Thoughts – Challenges and Best Practices
- Part VII: Summary