Summary (TL/DR): Data engineering in production is messy. From flaky APIs to schema drift, this section shares practical strategies and habits that help systems stay stable over time.
Even with clean code, solid tests, and smart design, field-tested data flows rarely run perfectly on the first try. APIs evolve, data structures drift, and edge cases crop up in unexpected ways. The key is not to avoid problems, but to design systems and habits that make handling them routine.
Here are some of the biggest challenges we faced—and how we addressed them.
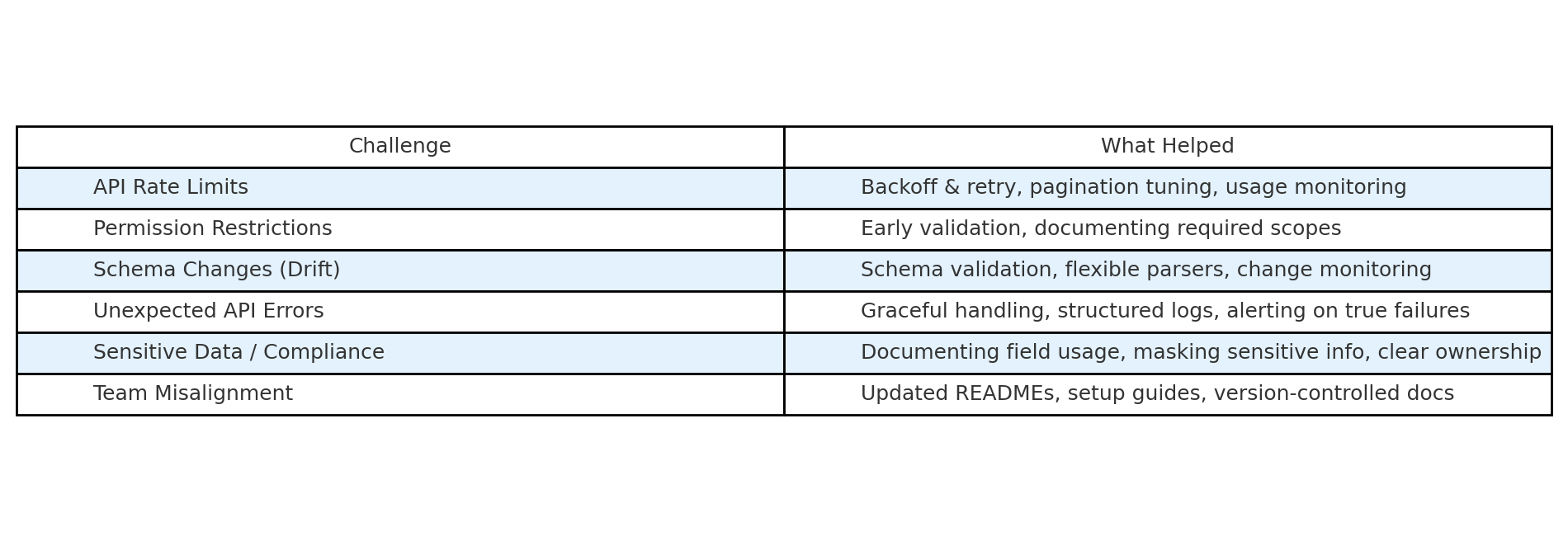
1. Handling API Rate Limits and Permission Restrictions
Many APIs enforce rate limits, meaning you can only make a certain number of requests in a given time window. Exceeding that limit can cause your sync to fail or even get your access temporarily blocked.
What helped:
- Backoff and retry logic – Automatically retrying failed requests with increasing delays
- Pagination tuning – Adjusting page sizes to reduce total calls
- Respecting quotas – Proactively monitoring usage before hitting hard limits
- Token refresh mechanisms – Ensuring long-running jobs didn’t fail due to expired auth
We also hit permission issues, especially when API tokens lacked access to certain endpoints. We learned to always document the required permissions for each connector and validate them early in the workflow.
2. Adapting to API Changes and Schema Drift
APIs and data sources often change without notice. A new field might be added, a type might change, or a required field could suddenly go missing.
What helped:
- Schema validation – Catching incompatible changes before they caused silent breakage
- Flexible parsers – Making our code resilient to new fields or optional values
- Change logs and monitoring – Tracking API changes over time and being alerted when diffs were detected
Being proactive here saved us from hours of manual debugging.
3. Managing Errors Gracefully
Not all errors are failures—many are expected scenarios that should be handled smoothly, like a 404 for a deleted record or a timeout during high load.
Best practices we followed:
- Structured logging – So errors were readable and traceable
- Alerting only on true failures – Avoiding noise from harmless retries
- Fail-safe design – Ensuring one connector’s failure didn’t block the entire pipeline
These patterns helped us maintain uptime and trust in our system, even when external systems were unpredictable.
4. Documentation and Compliance
Good documentation isn’t just for onboarding—it’s for safety, alignment, and future-proofing. Every time we added a new connector or updated pipeline logic, we also updated:
- README files – With setup instructions, rate limits, token scopes, and usage tips
- Process docs – Outlining retry behavior, schema structure, and known edge cases
- Compliance notes – Stating how we handled sensitive fields, such as user IDs or timestamps
This wasn’t just helpful—it was critical for data privacy and compliance. Clear documentation helped us ensure that everyone followed consistent practices, especially when dealing with personally identifiable information (PII) or restricted datasets.
Here’s a quick reference table summarizing some of the key issues we encountered—and the strategies that helped us manage them:
Final Thought
In-the-wild data engineering is full of edge cases. It’s not about building a perfect system once—it’s about building one that can adapt, recover, and evolve.
Strong habits around error handling, documentation, and system design go a long way in turning chaos into control.
In the final section, we’ll step back and reflect on what all of this adds up to—and how hands-on experience changes how you think about data fetching.
This article was written by Andrea Kuruppu, our superstar Data Engineer 🌟 Since we cover a lot of concepts here, we divided it into parts:
- Part I: The basics – Fetching the Data
- Part II: Data Processing and Pipeline Optimization
- Part III: Security – Managing Secrets and Authentication with a Proxy API
- Part IV: Version Control and Collaboration
- Part V: Testing, Debugging, and Deployment
- Part VI: Closing Thoughts – Challenges and Best Practices
- Part VII: Summary